
Em março deste ano, engenheiros da Amazon lançaram um artigo falando sobre como a mudança do modelo de microserviços para monolito reduziu os custos no serviço de monitoramento de vídeo em 90%. Às vezes, vale a pena refletir sobre o verdadeiro papel da arquitetura de microserviços, especialmente quando a tendência atual é componentizar cada vez mais, com tecnologias como edge computing, Serverless, micro-frontends, Function-as-a-Service (FaaS) e containerização. O futuro tende a granularizar o que antes eram serviços divididos por escopo até o ponto de se tornarem nanoserviços.
A arquitetura de microserviços possui uma série de vantagens, incluindo:
- Alta e fácil escalabilidade: Os microserviços permitem escalonar horizontalmente, concentrando-se nos componentes da aplicação que têm maior demanda computacional, permitindo o uso de autoscaling com aumento de custos e processamento linear.
- Modularidade: A separação de tarefas e propósitos impede que a aplicação pare de funcionar por completo quando uma parte dela apresenta algum erro e fica fora do ar.
- Flexibilidade: A divisão proporciona a capacidade de substituir máquinas sem afetar a disponibilidade da aplicação.
- Interoperabilidade de linguagens: É possível escrever um microserviço em C# e ele interagirá com uma aplicação em Java. Qualquer linguagem pode ser utilizada em qualquer combinação de microserviços.
No entanto, com todas essas vantagens, por que não utilizamos microserviços em todas as aplicações, sempre que possível? Na realidade, foi isso que aconteceu. Desenvolvedores de grandes empresas inspiraram o mercado contando suas histórias de como ajudaram o Google ou o Facebook a lidar com bilhões de usuários em todo o mundo, mantendo 99,999% de uptime, segurança impenetrável e tempos de resposta de nanossegundos para o percentil 99% das requisições.
Fantástico! Em um curto período de tempo, adotamos práticas de criação de microserviços, uso de message queues e implementamos pipelines de CI/CD em nuvem que fazem muito sentido na teoria. No entanto, caímos em muitas armadilhas quando não houve planejamento ou implementação adequados.
As armadilhas
O ponto mais óbvio é que a latência para realizar nossas operações aumenta. Isso também resulta em um aumento no tempo de resposta ao cliente, no custo de processamento e no envio de dados. É importante lembrar que deixamos de lidar com uma única máquina, onde o acesso às informações ocorre dentro da memória, do cache ou do disco da própria máquina, para lidar com a transferência de dados entre múltiplas máquinas (ou VMs). Isso torna todo o processo significativamente mais demorado, uma vez que envolve a serialização, a transferência e a deserialização de dados. A tabela abaixo ilustra um pouco dessa lógica. É importante destacar que o tempo de transmissão entre duas máquinas virtuais em um datacenter é muito menor do que o tempo de transferência via internet entre duas localidades diferentes.
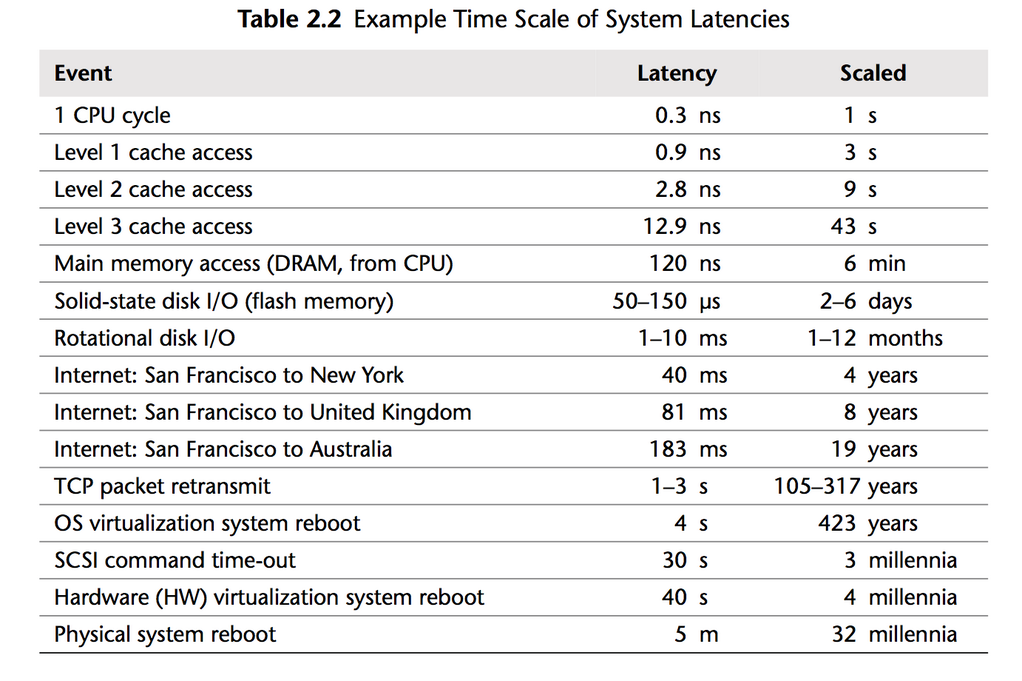
Extraído do livro Systems Performance: Enterprise and the Cloud
Números reais ou aproximados de latência entre máquinas virtuais em um datacenter variam consideravelmente dado o protocolo de comunicação, infraestrutura do datacenter, linguagem de programação, hardware, entre outros fatores. Azure disponibiliza formas de testar isso , outros grandes fornecedores possuem soluções similares, GCP por exemplo
Latência, entretanto, não é o único ponto aqui. O processamento adicional, a deserialização e serialização de mensagens em vez do acesso em memória em uma única máquina aumentam fundamentalmente os custos e o boilerplate necessários para o processamento de uma requisição. Esse custo se multiplica centenas de milhares de vezes, uma vez para cada requisição e para cada microserviço adicional envolvido na lógica de negócios.
Cruzar a ponte antes de chegar no rio
Netflix e outras gigantescas empresas começaram usando bases de código monolíticas e (depois de muitos anos, ao atingir valuation de múltiplos bilhões de dólares) migraram para microserviços quando já tinham usuários em múltiplos continentes
Agora você deve estar pensando: Mas meu produto não vai atingir o número de usuários que eu almejo! Não vou conseguir crescer e escalar de forma eficiente!
Shopify começou a migrar para componentes em 2020, quando já tinha dezenas de bilhões em valor de mercado e 2.1 milhões de usuários. Utilizando monólitos de código com Ruby
 Pode encontrar um artigo falando de como foi o processo aqui
Pode encontrar um artigo falando de como foi o processo aqui
Afogados em manutenção e boilerplate
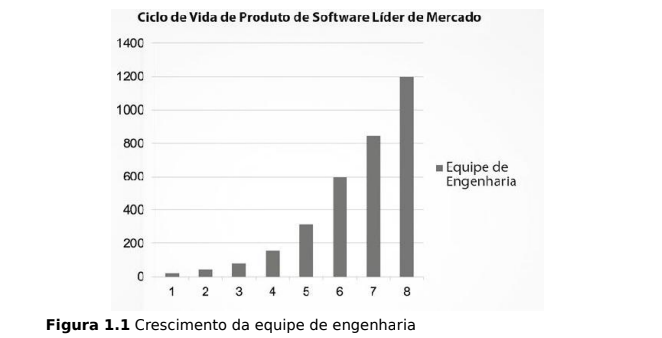
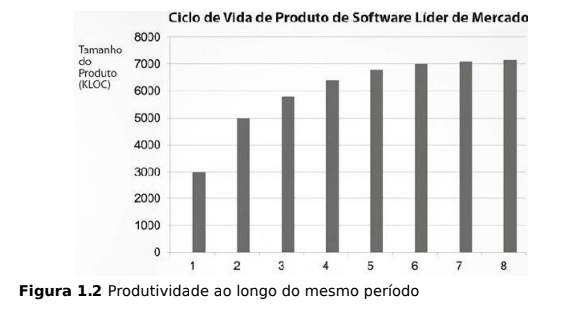
Em seu livro “Arquitetura Limpa,” Robert C. Martin (Uncle Bob) descreve um fenômeno originado da ausência de organização em um produto de software desorganizado. Isso ocorre quando os desenvolvedores não deram a devida atenção aos princípios de código limpo, arquitetura adequada e planejamento, entre outras razões que categorizam o código como bagunça. O seguinte acontece:
- Cresce o tamanho da equipe
- O tamanho do produto fica estagnado
- O custo para desenvolver código aumenta
 Mas por quê código fica ‘bagunçado’?
Mas por quê código fica ‘bagunçado’?
Há uma série de razões, mas dentre as principais
- Mudanças irregulares na regra de negócio
- Maior quantidade de código
- Falta de manutenção
- Ausência de padrões de projeto
- Maior número de programadores (pense em um livro com múltiplos autores, cada um com estilo diferente)
O que microserviços trazem para uma aplicação é complexidade
Imagine que você está desenvolvendo site de e-commerce, e nele você tem algumas funcionalidades para lidar, para simplificar as coisas vamos implementar 3 funções, registrar a compra, subtrair do inventário da empresa e incrementar o dinheiro recebido pelas vendas.
public async void ComprarItem(string produtoId, string clienteId, int valorProduto){
await tabelaCliente.realizarCompra(produtoId, clienteId);
await tabelaInventario.subtrairItem(produtoId);
await tabelaFinanceiro.incrementarConta(valorProduto);
}
Podemos até simplificar um pouco o processo, usando o princípio de transações atômicas do ACID e evitar transações parcialmente realizadas de gerarem problemas em caso de desligamento e defeitos, um try catch para gerar uma resposta para o request de forma síncrona, etc
public async void ComprarItem(string produtoId, string clienteId, int valorProduto){
bool isItemDisponivel = await repositorio.verificarItem(produtoId)
if(!isItemDisponivel) {
servicoEmail.EnviarProdutoIndisponivel(clienteId)
}
try {
await repositorio.realizarCompraItem(produtoId, clienteId, valorProduto) // Realiza compra, subtrai item, incrementa conta
}
catch (Exception e) {
return StatusCode(500)
}
}
O que acontece quando dividimos essas funcionalidades em máquinas diferentes?
Bem, além de algum código repetido para comunicação entre as partes, a parte da lógica seria similar
// Microserviço clientes
public async void ComprarItem(string produtoId, string clienteId, int valorProduto){
await tabelaCliente.realizarCompra(produtoId, clienteId);
servicoDeFila.enviarMensagem('ItemComprado', produtoId, clienteId, valorProduto)
}
// Microserviço inventario
public async void SubtrairItem(string produtoId, string clienteId, int valorProduto){
await tabelaInventario.subtrairItem(produtoId);
servicoDeFila.enviarMensagem('ItemSubtraido', produtoId, clienteId, valorProduto)
}
// Microserviço financeiro
public async void ComprarItem(string produtoId, string clienteId, int valorProduto){
await tabelaFinanceiro.incrementarConta(valorProduto);
}
E só isso, certo? Bem… Não. Temos que lembrar que nem sempre vai dar tudo certo, ás vezes quando tentamos subtrair um item, nem sempre temos a quantidade suficiente! Mas isso pode ser corrigido, com SAGA pattern quando uma transação downstream dá errado, nós fazemos o rollback das transações anteriores, além disso, precisamos de tratar a comunicação do clientes com o inventário de forma síncrona para que o cliente saiba se a compra está disponível ou não no momento que faz a compra.
// Microserviço clientes
public async void ComprarItem(string produtoId, string clienteId, int valorProduto){
await tabelaCliente.realizarCompra(produtoId, clienteId);
using (HttpClient client = new HttpClient())
{
try
{
// Faz uma solicitação HTTP POST
HttpResponseMessage response = await client.PostAsync(inventarioUrl);
if (response.IsSuccessStatusCode)
{
string responseBody = await response.Content.ReadAsStringAsync();
}
else
{
Console.WriteLine($"Erro na solicitação HTTP: {response.StatusCode}");
}
}
catch (Exception ex)
{
DevolverItem(produtoId, clienteId)
return StatusCode(500)
}
}
}
public async void DevolverItem(string produtoId, string clienteId){
await tabelaCliente.devolverCompra(produtoId, clienteId);
}
Alternativamente, se optarmos por um serviço assíncrono, podemos enviar uma mensagem de rollback no inventário
// Microserviço inventario
public async void SubtrairItem(string produtoId, string clienteId, int valorProduto){
try {
await tabelaInventario.subtrairItem(produtoId);
servicoDeFila.enviarMensagem('ItemSubtraido', produtoId, clienteId, valorProduto)
}
catch (Exception e) {
servicoDeFila.enviarMensagem('ItemSubtraidoRollback', produtoId, clienteId, valorProduto)
}
}
Agora estamos um pouco mais próximos de algo funcional. Mas o que acontece quando precisamos lidar com outras decisões e funcionalidades? O que acontece quando precisamos enviar uma mensagem de e-mail confirmando o pedido ao cliente ou lidar com um erro ao tentar gravar a incrementação no financeiro?
Todas essas perguntas têm respostas e soluções conhecidas e utilizadas, como salvaguardas, persistência em fila e o padrão SAGA. No entanto, essas soluções aumentam significativamente a complexidade do nosso código. Para lidar com uma base de código assim, é necessário uma equipe com maior conhecimento técnico dos padrões envolvidos, atenção aos detalhes, tempo investido em refatoração e manutenção de funcionalidades, além de um bom planejamento e sólidos padrões de projeto.
Acreditamos que podemos deixar times de desenvolvedores responsáveis por microserviços individuais, especialistas em seu próprio campo, em um ambiente onde trabalham apenas em funcionalidades de seus respectivos domínios, interagindo somente com aqueles envolvidos em seus próprios projetos. No entanto, sabemos que isso raramente acontece. Projetos nessa configuração exigem reuniões entre times para desenvolver features que envolvem microserviços diferentes, com cada equipe seguindo seu próprio calendário e trabalhando em features de diferentes contextos. Isso não é algo que atrapalhe o desenvolvimento quando ocorre ocasionalmente, mas em projetos mais complexos ou projetos sem um bom planejamento, isso acaba se tornando mais comum do que exceção.
Um cenário desse tipo não parece uma grande dificuldade, afinal, se microserviços diferentes têm padrões de código semelhantes, uma equipe pode trabalhar em múltiplos ambientes e integrá-los sem dificuldade. No entanto, isso elimina um dos pontos positivos de estarmos utilizando esse tipo de arquitetura em primeiro lugar, pois estamos perdendo a flexibilidade de utilizar diferentes tipos de padrões ou linguagens. Com isso, perdemos a capacidade de escrever um microserviço em C# e outro em Java, por exemplo.
DRY? esqueça
Sabe aquilo que usamos com o propósito de reusabilidade, que talvez seja um dos pilares da programação moderna? Funções. Um dos maiores objetivos das funções é referenciar uma parte de código que já foi escrita ou pensada. No entanto, agora, você precisa buscá-la em outro microserviço, ou o que é mais comum: escrevê-la novamente. Um dos princípios ao qual estamos mais acostumados (DRY, Don’t Repeat Yourself) deve ser completamente ignorado quando a alternativa é expor funções para outros escopos e máquinas virtuais, escrever blocos try-catch quando chamarmos essas funções, etc.
Não todos os microserviços vão ter um conjunto de responsabilidades e funcionalidades completamente diferentes. Dois contextos podem precisar formatar uma string, fazer um parse de um XML e transformá-lo em CSV, buscar imagens em um bucket S3, catalogá-las por data e inserir uma marca d’água da empresa, gerar um PDF e criptografá-lo com os primeiros dígitos do CPF de um cliente. O que fazemos então? Criamos um “nanoserviço” para cada funcionalidade? Assim, o tempo de execução de código que antes era de “nanossegundos” é multiplicado por vários fatores de 10 e passa a durar alguns microssegundos. Pode não parecer muito, para nós que mal notamos um segundo passar ao carregar uma página web, mas estamos multiplicando o tempo necessário por mil e também aumentando o custo para realizar aquela operação. Talvez você não note, mas com certeza a conta ao final do mês será mais alta.
Então, repetimos nosso código, criamos a mesma função, copiamos o código já existente linha por linha em outro repositório. Agora precisamos escrever testes para o mesmo código duas vezes. O que acontece quando deixamos de usar AWS S3 buckets para usar Azure? Agora também precisamos modificar nosso código em dois lugares diferentes, ou o mais comum: esquecemos que temos aquele código em dois lugares diferentes e lidamos com um bug mais tarde. Precisamos modificar nosso código em dois lugares diferentes, então abrimos dois pull requests (monorepos existem, mas são a exceção, não a regra), em duas pipelines, onde para fazer o build e os testes das duas funções vão utilizar o dobro do tempo, demandar mais desenvolvedores e atrasar o desenvolvimento de uma funcionalidade que seria simples em uma só base de código.
Além do mar
Microserviços não são necessariamente a escolha errada. Chega um ponto em que pode fazer mais sentido adotar microserviços à medida que sua aplicação cresce em tamanho, número de usuários e recursos disponíveis (orçamento também).
Mas como saber? É necessário analisar os prós e contras para decidir, os custos de mudança podem ser significativos? Minha aplicação precisa de 99,99% de uptime? Eu tenho uma equipe qualificada para lidar com a migração e manutenção da nova infraestrutura? De que outras formas posso lidar com meus problemas de escalabilidade sem precisar adotar a arquitetura de microserviços?
Microserviços não são intrinsecamente desorganizados. É possível manter uma arquitetura bem estruturada e limpa, como explicado por Uncle Bob em seu blog
O que estou tentando demonstrar é que o hype dos últimos anos nos deixou com a impressão de que microserviços são a solução para todos os tipos de aplicações, quando na verdade muitas implementações não fazem sentido. Algumas equipes escolhem adotar essa arquitetura simplesmente porque é a mais recente, brilhante ou atrativa, o que facilita a venda para o cliente. As decisões de arquitetura precisam ser baseadas em dados, conhecimento técnico e nas particularidades de cada produto.
A adoção da arquitetura de microserviços faz sentido se você já sabe que sua aplicação terá uma alta demanda de acessos ou exigirá uma grande capacidade computacional (ou ambos), como o lançamento de um novo produto de uma grande empresa ou uma grande campanha de marketing em que você espera que milhões de pessoas acessem sua aplicação simultaneamente. Nesses casos, as vantagens do autoscaling e do escalonamento horizontal se tornam necessárias para manter a estabilidade da aplicação em um curto período de tempo.
A adoção de microserviços busca aproveitar a principal vantagem desse estilo de arquitetura, que é a escalabilidade, além de lidar com as necessidades de aplicações que exigem um alto volume de processamento e a capacidade de escalar os custos de capacidade de forma linear e fluida.
Então, quando considerar a adoção da arquitetura de microserviços?
Bem, se você faz parte de uma multinacional com milhões de usuários, em uma empresa cuja principal função está próxima da tecnologia, com recursos financeiros substanciais e uma equipe que pretende manter o sistema por um longo período, mesmo após o desenvolvimento inicial, para realizar a manutenção e aprimoramentos em uma grande rede de aplicações com alta demanda técnica, parabéns! Talvez os microserviços se encaixem na realidade do seu projeto!